안전한 거래를 책임지는 OCR 기능 개선 기록
이미지에서 글자를 검출하는 모델의 성능과 추론 속도를 개선해 모니터링 시스템의 실시간 어뷰징 탐지 능력을 강화하여 거래를 더 안전하게 만드는데 기여했습니다.
번개장터는 구매자가 안심하고 거래할 수 있도록, 채팅 과정에서 사기 패턴을 탐지하는 모니터링 시스템을 도입해 운영하고 있습니다. 그러나 시스템이 점차 고도화되면서, 일부 사용자들이 이를 우회하는 방식으로 어뷰징 패턴을 발전시키고 있습니다. 예를 들어, 한 판매자가 자신의 계좌번호나 휴대폰 번호가 담긴 사진을 구매자에게 공유한 뒤, 번개장터의 모니터링이 닿지 않는 외부 채널로 유도해 사기 피해를 입히는 사례가 다수 발생하고 있습니다.
이와 같은 어뷰징 시도로부터 구매자를 보호하기 위해, 번개장터 데이터랩은 오래전부터 OCR(Optical Character Recognition) 시스템을 도입해 이미지에서 글자를 탐지하고 검출하는 작업을 수행해 왔습니다. 그러다 2024년 8월 부터는 판매자는 더 신뢰받고, 구매자들은 안심할 수 있도록 번개장터의 모든 거래 방식을 안전결제로 일원화하는 변화가 생겼습니다. 이에 따라 OCR 시스템의 이미지 내 글자 탐지 정확도와 시스템 효율성 또한 더 향상시킬 필요성이 제기되었습니다.
이를 해결하고자 데이터랩은 2024년 3분기에 데이터 사이언티스트 Blank(김선식)와 Tobi(이동빈)를 중심으로 OCR 모델의 성능과 추론 속도를 개선하는 프로젝트를 진행했습니다.
OCR 프로세스 개요
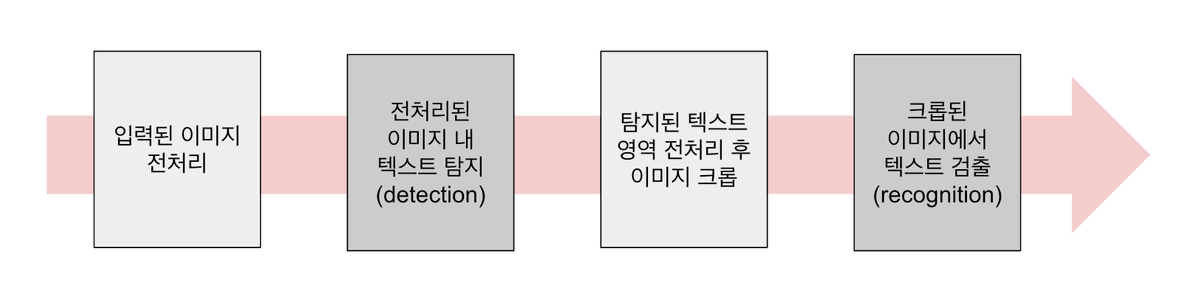
먼저, 입력된 이미지에서 글자를 검출하는 과정은 위와 같이 4개의 단계로 도식화할 수 있습니다. 이 중, 텍스트를 탐지하는 두 번째 단계와 크롭된 텍스트 이미지에서 텍스트를 검출하는 네 번째 단계에는 각각 다른 OCR 모델이 사용됩니다. 또한, 이미지 전처리를 수행하는 첫 번째 단계와 탐지된 텍스트 영역을 전처리하는 세 번째 단계에서도 추론 로직이 필요하며, 이는 시스템의 완성도를 높이는 데 중요한 역할을 합니다.

위의 4개의 이미지를 통해 과정을 더 자세히 살펴보겠습니다. 시스템에 입력된 이미지는 위의 첫 번째 이미지와 같이 정해진 사이즈로 조정됩니다. 이후에는 탐지기(detector)가 두 번째 이미지와 같이 텍스트 영역을 초록색과 같이 표시합니다. 두 번째 사진에 표시된 것처럼, 현재 단계에서는 메인 간판 글자 뿐 아니라 비닐 후드에 비친 글자와 같은 노이즈가 탐지 결과에 포함되어 있습니다. 이를 적절히 전처리하여 세 번째 이미지처럼 탐지된 영역을 사각형 박스 형태로 구획하여 크롭합니다. 크롭된 이미지는 검출기(recognizer)에 전달되고, 네 번째 이미지와 같이 최종적으로 텍스트가 검출됩니다.
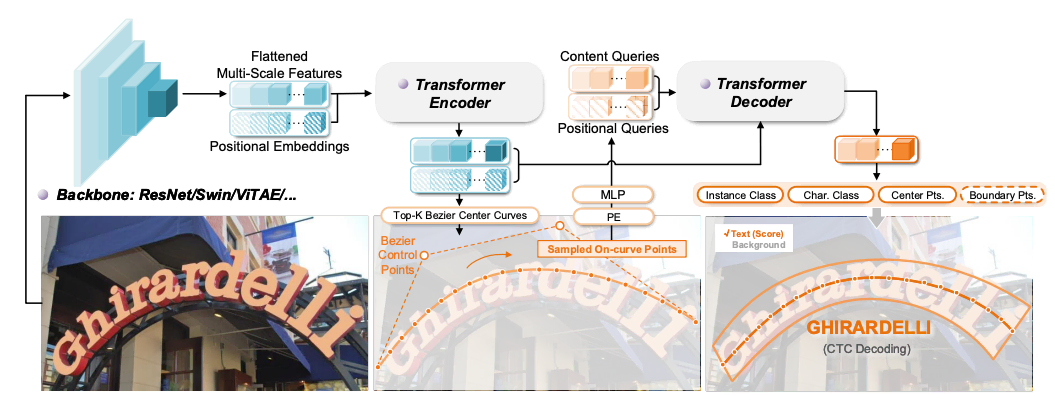
이렇게 단계를 나눠서 하는 방법과 더불어, 최근에는 텍스트 탐지와 검출을 한번에 하는 모델에 대한 연구도 많이 진행되고 있습니다. 예를 들어, 위 이미지와 같이 글자 영역을 가로지르는 가상의 곡선 위에 있는 텍스트를 바로 인식하는 DeepSolo나 ABCNet 모델은 탐지와 검출을 한번에 수행합니다. 이러한 모델을 활용하면 탐지와 검출을 위한 모델을 따로 학습시키고 관리할 필요도 없고, 탐지된 텍스트 영역을 전처리하는 로직을 따로 구현할 필요도 없어 시스템이 간소화되는 장점이 있습니다. 하지만, 시뮬레이션 데이터로 추론 속도를 비교해본 결과, 이미지 한 장을 처리하는데 소요되는 총 시간은 탐지와 검출을 별도의 심플한 모델에서 수행하는 것보다 이를 하나로 합친 고도화된 모델에서 오히려 더 오래 걸리는 경향이 있었습니다. 이미지 처리 속도를 높여 어뷰징 시도를 실시간으로 탐지하는 것이 이번 프로젝트의 핵심 목표였기 때문에, 구현이 다소 복잡해지더라도 탐지와 검출 모델을 분리한 아키텍쳐를 선택하게 되었습니다.
OCR 프로세스 단계별 개선사항
앞서 설명드린 4가지 단계 각각의 구현을 위해 고려했던 기술적 디테일은 이어지는 4개 챕터에 나눠서 설명하겠습니다.
1. 이미지 전처리 단계
텍스트 영역 탐지 모델(detector)은 고정된 크기의 입력 이미지를 받아 각 픽셀이 텍스트 영역에 해당하는지에 대한 신호의 강도를 계산해 0에서 1사이의 값으로 반환하는 신경망 모델입니다. 그렇기 때문에 이 단계에서는 입력된 이미지를 확대 또는 축소해 정해진 크기의 정사각형 이미지로 변환하는 작업을 먼저 수행합니다.

이때, 시스템에 입력되는 대부분의 이미지는 가로나 세로가 더 긴 직사각형 형태이기 때문에, 이를 그대로 정사각형으로 변환하면 길이가 짧은 쪽에서 왜곡이 발생합니다. 예시를 위해 위의 도식화에서 사용한 이미지를 가로, 세로 방향으로 크롭한 다음 정사각형으로 변환해 1, 3번 이미지를 만들었을 때, 왜곡이 발생한 것을 확인할 수 있습니다.
기존 시스템에서는 이에 대한 별다른 처리 없이 왜곡된 이미지를 그대로 사용했지만, 시스템을 개선하며 2, 4번 이미지와 같이 더 짧은 쪽에 하얀색 픽셀을 채워 이미지를 정사각형으로 만든 뒤 이미지를 변환하도록 수정하며 왜곡을 없앴습니다. 추가적으로 신경망 모델은 너무 큰 입력값에 민감하게 반응하므로, 0에서 255 사이의 값을 갖는 픽셀 값에 정규화 연산을 적용했습니다.
2. 텍스트 영역 탐지 모델(detector)
기존 시스템에서는 시중에 공개된 모델인 PaddleOCR의 사전학습된 detector를 그대로 다운받아 사용하고 있었습니다. 하지만 일부 유저들의 탐지를 회피하기 위한 어뷰징 패턴이 고도화되면서, 사전학습된 모델로는 탐지되지 않는 케이스들이 점점 생겨나게 되었습니다. 이에 대응하기 위해, PaddleOCR의 detector 모델인 DBNet을 구현하고 탐지 성능이 낮은 케이스들에 대한 데이터셋을 보강해 모델을 직접 학습시켰습니다.
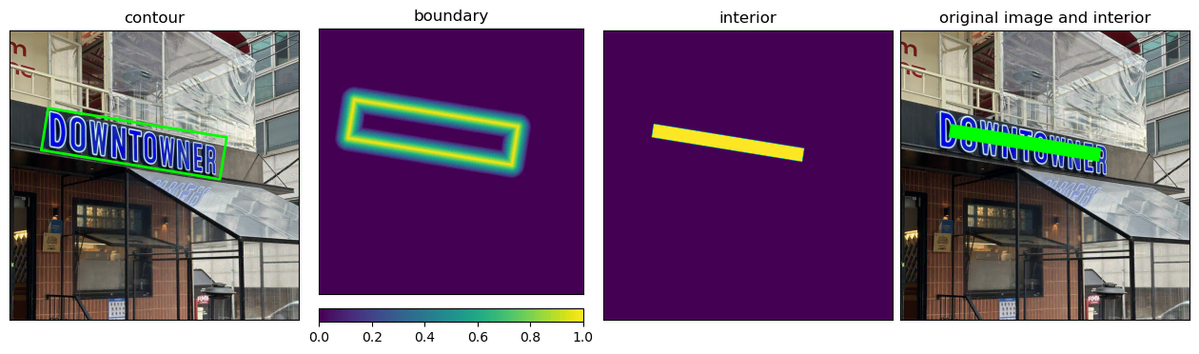
위 이미지에서 도식화한 것처럼, 학습 데이터에는 텍스트 영역이 외곽선(contour)을 기준으로 경계(boundary)와 내부(interior)로 분리되어 저장됩니다. 경계는 외곽선에서 가까운 정도에 따라 0에서 1 사이의 값을 부여한 주변 부분, 내부는 외곽선 영역을 정해진 비율만큼 축소시킨 부분을 의미합니다. 경계 영역은 픽셀별로 정의된 값과 모델이 예측한 값의 차이가 최소화될 수 있도록 학습시키고, 내부 영역은 1로 채워 모델이 픽셀별로 이진분류를 시행할 수 있도록 학습시킵니다. 이 과정을 통해 모델은 텍스트 영역의 경계를 더 잘 찾아내고, 내부 영역에 해당하는 픽셀들의 확률값을 더 큰 값으로 반환할 수 있게 됩니다.
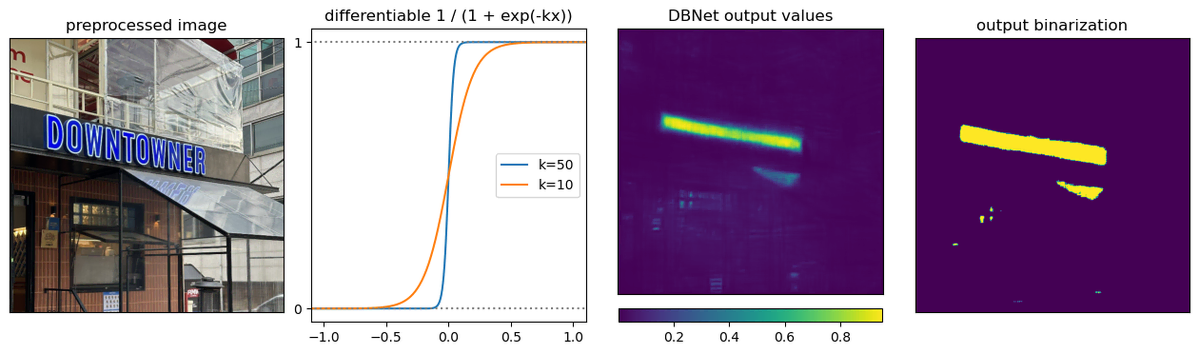
DBNet이라는 이름은 이 모델의 Differentiable Binarization이라는 아이디어의 약자를 가지고 만들어졌습니다. 이진화(Binarization)는 위의 세 번째 플랏과 같이 각 픽셀에 대해 detector가 반환하는 값을 위의 네 번째 플랏과 같이 0또는 1로 변환하는 과정을 의미합니다. DBNet 모델에서는 이 값을 반환하는 함수가 위의 두 번째 플랏에서 보이는 것처럼 미분 가능한(Differentiable) 시그모이드 함수 형태로 정의되어 있어 이러한 이름이 붙었습니다. 이 함수의 기울기(k)를 크게 설정하면 그만큼 학습에 필요한 정보의 양인 그래디언트도 큰 값으로 계산되기 때문에, 텍스트 영역과 아닌 영역을 더 확실하게 구분하도록 모델을 학습시킬 수 있게 됩니다.
3. 텍스트 영역 전처리 단계
텍스트 검출 모델(recognizer)은 고정된 크기의 입력 이미지에 있는 텍스트를 추출하는 신경망 모델입니다. 따라서, 이전 단계에서 이진화된 이미지를 기반으로 텍스트 영역만 고정된 크기로 크롭하기 위한 전처리 로직이 필요합니다.
이 과정에서 이진화된 이미지의 텍스트 영역 외곽선을 필터링 없이 그대로 사용하면, 노이즈 영역이 포함된 텍스트 영역이 생성되어 검출 품질이 저하될 수 있습니다. 기존 시스템에서는 이러한 필터링 로직이 제대로 구현되지 않아 아래 이미지들로 도식화할 수 있는 전처리 과정을 새롭게 도입했습니다.
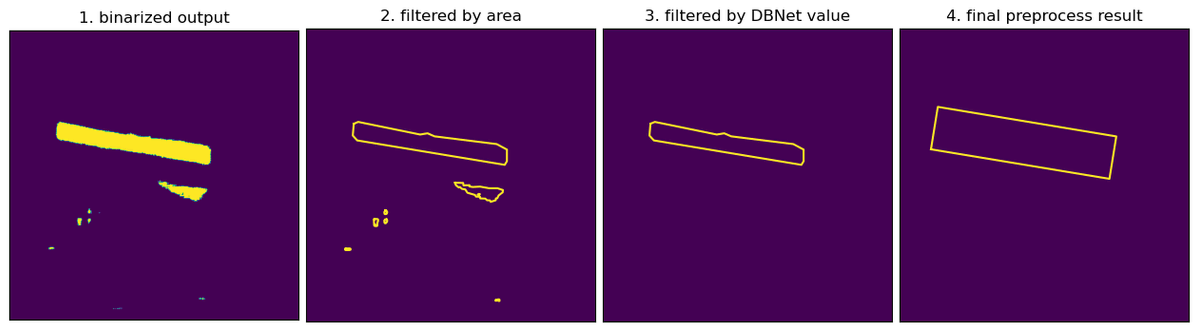
DBNet의 출력 결과를 이진화하면 첫 번째 이미지와 같은 결과가 생성됩니다. 초기 단계에서는 1로 이진화된 노란색 픽셀 그룹을 둘러싸는 외곽선을 도출하며, 이때 내부 면적이 너무 작은 외곽선은 제거하여 두 번째 이미지와 같은 중간 결과를 얻습니다. 그다음, 외곽선 내부 픽셀들의 DBNet 출력값 평균이 설정된 임계값을 넘지 못하는 외곽선을 추가로 제거하면 세 번째 이미지와 같은 결과를 얻을 수 있습니다. 이후, 남은 외곽선을 사각형 형태로 만들고, 앞서 텍스트 영역을 축소시킨 비율만큼 이 사각형을 확대시키면 네 번째 이미지와 같은 최종 결과를 얻습니다. 이 사각형을 기준으로 이미지를 크롭해서 텍스트 검출 모델에 전달합니다.
4. 텍스트 검출 모델(recognizer)
박스에 맞춰 크롭된 이미지에서 텍스트를 검출하는 모델(recognizer)은 컴퓨터 비전 분야에서 아직도 활발하게 연구되고 있는 주제입니다. 최근에는 트랜스포머 모델이 분야를 가리지 않고 활발하게 사용되고 있고, 텍스트 검출 문제에서도 이를 활용한 모델이 높은 검출 정확도를 보인다는 연구 결과들이 보고되고 있습니다.
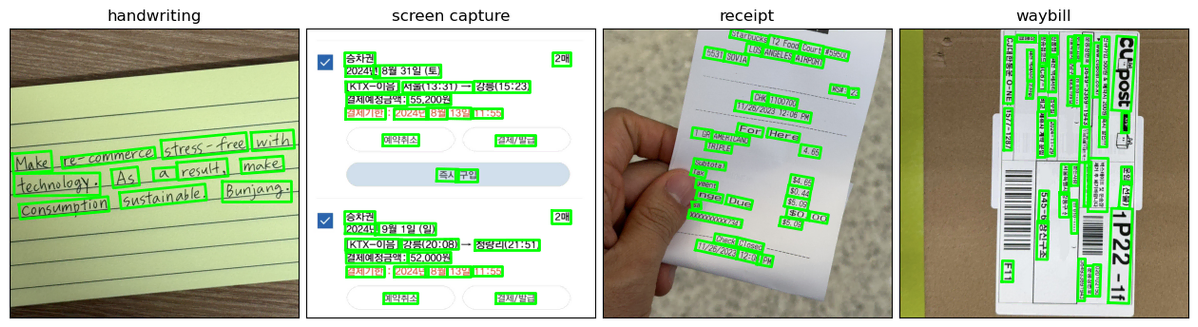
하지만 실제 서비스 환경에서 처리되는 이미지들은 대부분 위 예시들에서와 같이 여러개의 텍스트 박스들을 포함하고 있고, 이를 대량으로 빠르게 처리할 수 있어야 어뷰징을 실시간으로 모니터링할 수 있습니다. 따라서, 텍스트 검출의 정확도 뿐만 아니라 초당 처리량(FPS)도 사용할 모델을 선정하는데 중요한 기준이 되었기 때문에 CRNN을 텍스트 검출 모델로 선정하게 되었습니다. 이 모델은 상대적으로 추론 속도가 빠른 CNN과 RNN을 이어서 텍스트 시퀀스를 예측하기 때문에 FPS가 훨씬 높습니다. 트랜스포머 기반 최신 모델인 DTrOCR 논문의 벤치마크를 참고해봐도 CRNN은 이런 최신 모델들보다 탐지 정확도는 떨어지지만 이 단점을 상회할 정도로 처리 속도가 빠릅니다. 이런 이유 때문에 CRNN이 실시간 어뷰징 모니터링 시스템 구현을 위한 현실적인 선택지라고 판단했습니다.

기존 시스템에서도 CRNN 모델을 사용했지만, 이미지를 고정된 크기로 조정하는 과정에서 발생하는 왜곡을 최소화하기 위해 이미지의 가로 길이는 임의의 값을 갖도록 허용하는 방식을 적용했습니다. 그러나 이로 인해 탐지된 텍스트 박스를 하나씩 순차적으로 처리해야 했고, 결과적으로 FPS가 기대치를 충족하지 못했습니다. 이를 해결하기 위해, 위의 실제 입력 이미지 및 예측 사례에서와 같이 하얀색 픽셀을 추가로 채워 이미지 크기를 동일하게 조정하는 방식으로 수정했습니다. 이 방법을 통해 왜곡은 최소화하면서 입력 이미지의 크기는 고정시킬 수 있게 되었고, 여러 텍스트 박스의 이미지를 한 번의 배치로 처리할 수 있게 되어 FPS 성능을 크게 향상시켰습니다.
성능 평가 결과
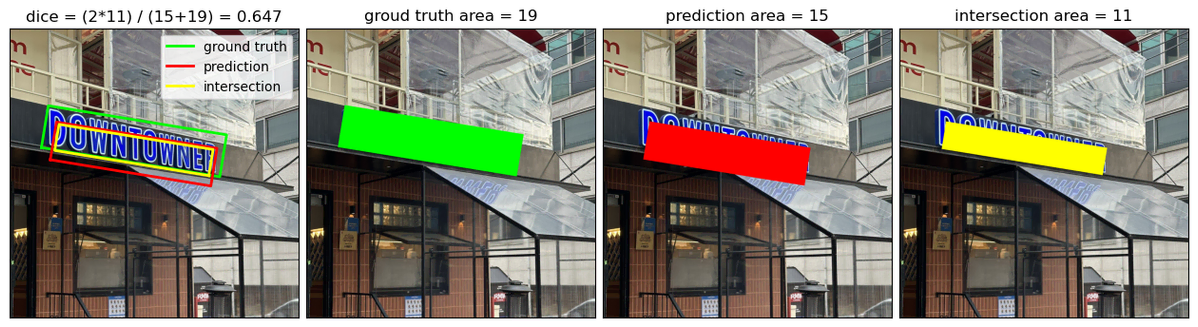
두 시스템의 detector는 예측된 텍스트 영역과 실제 텍스트 영역의 겹침 정도를 측정하는 Dice 점수를 사용해 평가합니다. Dice 점수는 위에서 도식화한 것처럼 두 영역이 겹친 영역의 면적(노란색)에 2를 곱한 값을 각 영역의 면적(빨간색, 초록색)를 더한 값으로 나누어 계산됩니다. 이 점수는 0에서 1 사이의 값을 가지며, 값이 클수록 detector가 실제 텍스트 영역을 정확히 탐지했다는 것을 의미합니다.
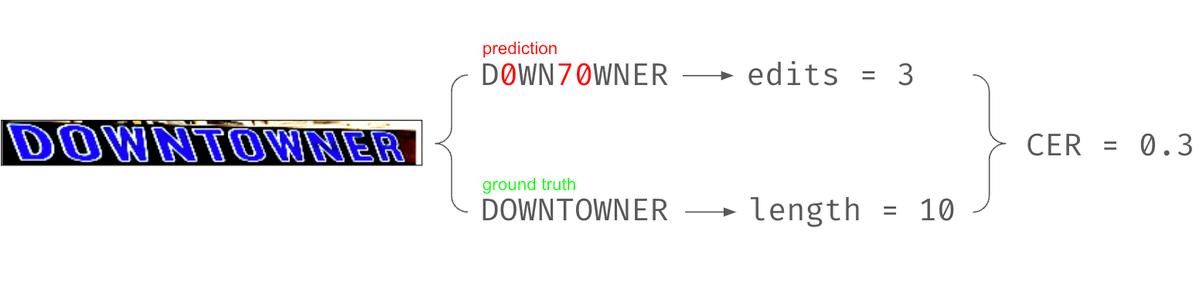
두 시스템의 recognizer는 예측된 텍스트가 실제 텍스트가 되려면 최소한 몇 번의 편집이 필요한지를 측정하는 문자 예측 오류율(CER)에 따라 비교합니다. 구체적으로, CER은 예측된 텍스트의 글자들이 몇 번 삽입, 대체, 삭제되어야 실제 텍스트가 되는지를 센 다음 이를 실제 텍스트의 글자 수로 나눈 값으로 정의됩니다. 위 예시에선 잘못 예측된 숫자 0 두개를 대문자 O, 숫자 7을 대문자 T로 대체하는데 필요한 편집 수 3을 실제 텍스트의 글자수 10으로 나눠 CER이 0.3이 되었습니다. 만약 예측된 텍스트가 실제 텍스트와 완전히 동일해서 어떤 편집도 필요하지 않다면 이 값은 0이 될 것이므로, CER이 낮을수록 recognizer가 텍스트를 잘 검출했음을 의미합니다.
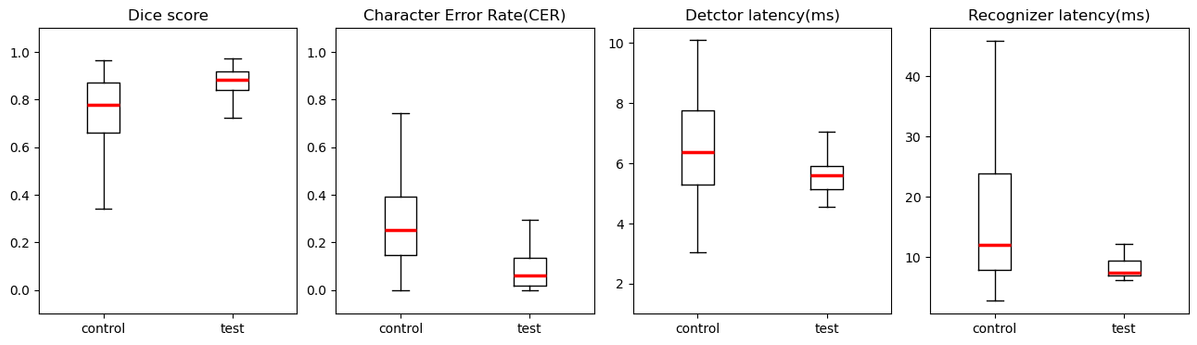
설명한 척도 외에도, detector 및 recognizer 처리 지연 시간(레이턴시)을 기준으로 기존 모델(control)과 신규 모델(test)을 비교했습니다. 이를 위해 번개장터에 업로드된 실제 텍스트 이미지 중 랜덤하게 300장을 선별하고 정제한 후, 각 지표를 수집하여 박스플롯 형태로 분석했습니다. 첫 번째, 두 번째 플랏을 통해 신규 모델의 Dice 점수 분포가 기존 모델보다 더 높게 분포되어 있고, CER 분포는 더 낮게 나타나는 것을 확인할 수 있었습니다. 중위값을 기준으로 보면 detector의 Dice 점수는 기존 대비 14% 증가했고, recognizer의 CER은 기존의 24% 수준으로 감소했습니다. 또한, 네 번째 플랏을 통해 신규 recognizer 모델의 레이턴시 분포가 기존에 비해 현저하게 낮아진 것을 확인할 수 있습니다. 중위값을 기준으로 봐도 recognizer의 레이턴시가 기존의 62% 수준으로 감소했습니다.
이 결과를 바탕으로 성능과 속도 측면에서 모두 유의미한 개선이 이루어졌음을 확인했으며, 기존 모델을 대체할 새로운 모델로 채택하게 되었습니다.
결론 및 향후 개선 방향
앞서 설명드린 것처럼 이번 프로젝트에서는 어뷰징을 실시간으로 탐지할 수 있는 효율적인 시스템 구현에 초점을 맞췄습니다. 텍스트 탐지 및 검출 모델 자체에 큰 변화를 주기보다는, 데이터 전처리 방식을 개선하여 성능을 높이고, 모델 호출 로직을 최적화해 처리 속도를 향상시켰습니다. 이를 통해 개선된 모델 기반의 어뷰징 탐지 시스템은 현재 운영 환경에 완전히 배포되어, 번개장터 유저들을 어뷰징을 통한 사기 위험으로부터 보호하는 데 기여하고 있습니다.
물론 향후 개선 가능성도 여전히 남아 있습니다. 최근 시장에 등장한 트랜스포머 아키텍처에 특화된 하드웨어를 활용하면, 현재 추론 속도 제약으로 도입하지 못했던 트랜스포머 기반 모델을 적용해 성능을 더욱 높이면서도 속도를 유지할 수 있을 것으로 기대됩니다. 또한, 운영 환경에서 보고되는 엣지 케이스 데이터를 지속적으로 수집하고 보강해 모델을 추가 학습시킴으로써 성능을 더욱 향상시킬 수 있습니다. 앞으로도 데이터랩은 번개장터 사용자들이 보다 안전하게 거래할 수 있는 환경을 제공하기 위해 끊임없이 연구하고 노력하겠습니다.
참고문헌
[1] Liao, Minghui, et al. "Real-time scene text detection with differentiable binarization." Proceedings of the AAAI conference on artificial intelligence. Vol. 34. No. 07. 2020.
[2] Shi, Baoguang, Xiang Bai, and Cong Yao. "An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition." IEEE transactions on pattern analysis and machine intelligence 39.11 (2016): 2298-2304.
[3] Fujitake, Masato. "Dtrocr: Decoder-only transformer for optical character recognition." Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2024.
[4] Du, Yuning, et al. "Pp-ocr: A practical ultra lightweight ocr system." arXiv preprint arXiv:2009.09941 (2020).
[5] Graves, Alex, et al. "Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks." Proceedings of the 23rd international conference on Machine learning. 2006.
[6] Liu, Yuliang, et al. "Abcnet: Real-time scene text spotting with adaptive bezier-curve network." proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
[7] Ye, Maoyuan, et al. "Deepsolo: Let transformer decoder with explicit points solo for text spotting." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
더보기

상품 등록 카테고리 추천 모델 개발 과정

번개장터의 디지털 광고 시스템 1: 소개
